[导读] 数据压缩与重复数据删除两种技术有何区别与联系呢?实际中又该如何正确应用呢?笔者之前对数据压缩原理和技术没有研究,因此做了点功课,查阅整理了相关资料,并与重复数据删除技术进行对比分析。
面对数据的急剧膨胀,企业需要不断购置大量的存储设备来应对不断增长的存储需求。然而,单纯地提高存储容量,这似乎并不能从根本解决问题。首先,存储设备的采购预算越来越高,大多数企业难以承受如此巨大的开支。其次,随着数据中心的扩大,存储管理成本、占用空间、制冷能力、能耗等也都变得越来越严重,其中能耗尤为突出。再者,大量的异构物理存储资源大大增加了存储管理的复杂性,容易造成存储资源浪费和利用效率不高。因此,我们需要另辟蹊径来解决信息的急剧增长问题,堵住数据“井喷”。高效存储理念正是为此而提出的,它旨在缓解存储系统的空间增长问题,缩减数据占用空间,简化存储管理,最大程度地利用已有资源,降低成本。目前业界公认的五项高效存储技术分别是数据压缩、重复数据删除、自动精简配置、自动分层存储和存储虚拟化。目前,数据压缩和重复数据删除是实现数据缩减的两种关键技术。简而言之,数据压缩技术通过对数据重新编码来降低冗余度,而重复数据删除技术侧重于删除重复的数据块,从而实现数据容量缩减的目的。
数据压缩[1][2]
数据压缩的起源可以追溯到信息论之父香农(Shannon)在1947年提出的香农编码。1952年霍夫曼(Huffman)提出了第一种实用性的编码算法实现了数据压缩,该算法至今仍在广泛使用。1977年以色列数学家Jacob Ziv 和Abraham Lempel提出了一种全新的数据压缩编码方式,Lempel-Ziv系列算法(LZ77和LZ78,以及若干变种)凭借其简单高效等优越特性,最终成为目前主要数据压缩算法的基础。LZ系列算法属于无损数据压缩算法范畴,采用词曲编码技术实现,目前主要包括LZ77、LZSS、LZ78和LZW四种主流算法。可以归纳为两类:
第一类词典法的想法是企图查找正在压缩的字符序列是否在前面的输入数据中出现过,如果是,则用指向早期出现过的字符串的“指针”替代重复的字符串。这种编码思想如图1所示。这里的“词典”是隐含的,指用以前处理过的数据。这类编码中的所有算法都是以Abraham Lempel和Jakob Ziv在1977年开发和发表的算法(称为LZ77算法)为基础。此算法的一个改进算法是由Storer和Szymanski在1982年开发的,称为LZSS算法。
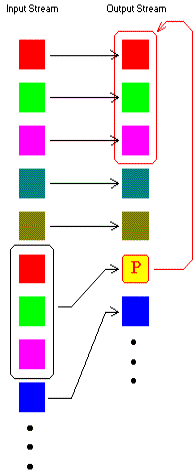
图1 第一类词典法编码概念
第二类算法的想法是企图从输入的数据中创建一个“短语词典(dictionary of the phrases)”。编码数据过程中当遇到已经在词典中出现的“短语”时,编码器就输出这个词典中的短语的“索引号”,而不是短语本身。这个概念如图2所示。A.Lempel和J.Ziv在1978年首次发表了介绍这种编码方法的文章,称为LZ78。在他们的研究基础上,Terry A.Welch在1984年发表对这种编码算法进行了改进的文章,并首先在高速硬盘控制器上应用了这种算法。因此后来把这种编码方法称为LZW(Lempel-Ziv Walch)压缩编码。
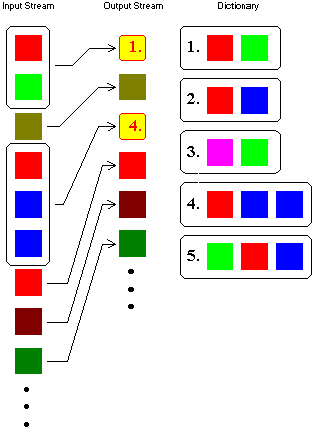
图2 第二类词典法编码概念
Lempel-Ziv系列算法的基本思路是用位置信息替代原始数据从而实现压缩,解压缩时则根据位置信息实现数据的还原,因此又被称作"字典式"编码。目前存储应用中压缩算法的工业标准(ANSI、QIC、IETF、FRF、TIA/EIA)是LZS(Lempel-Ziv-Stac),由Stac公司提出并获得专利,当前该专利权的所有者是Hifn, Inc.。数据压缩的应用可以显著降低待处理和存储的数据量,一般情况下可实现2:1 ~ 3:1的压缩比。
LZ77算法[3]
1977年,Jacob Ziv和Abraham Lempel描述了一种基于滑动窗口缓存的技术,该缓存用于保存最近刚刚处理的文本(J. Ziv and A. Lempel, “A Universal Algorithm for Sequential Data Compression”, IEEE Transaction on Information Theory, May 1977)。这个算法一般称为LZ77。LZ77和它的变体发现,在正文流中词汇和短语(GIF中的图像模式)很可能会出现重复。当出现一个重复时,重复的序列可以用一个短的编码来代替。压缩程序扫描这样的重复,同时生成编码来代替重复序列。随着时间的过去,编码可以重用来捕获新的序列。算法必须设计成解压程序能够在编码和原始数据序列推导出当前的映射。
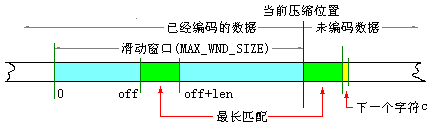
图3 LZ77算法示意图
LZ77(及其变体)的压缩算法使用了两个缓存。滑动历史缓存包含了前面处理过的N个源字符,前向缓存包含了将要处理的下面L个字符。算法尝试将前向缓存开始的两个或多个字符与滑动历史缓存中的字符串相匹配。如果没有发现匹配,前向缓存的第一个字符作为9 bit的字符输出并且移入滑动窗口,滑动窗口中最久的字符被移出。如果找到匹配,算法继续扫描以找出最长的匹配。然后匹配字符串作为三元组输出(指示标记、指针和长度)。对于K个字符的字符串,滑动窗口中最久的K个字符被移出,并且被编码的K个字符被移入窗口。
尽管LZ77是有效的,对于当前的输入情况也是合适的,但是存在一些不足。算法使用了有限的窗口在以前的文本中查找匹配,对于相对于窗口大小来说非常长的文本块,很多可能的匹配就会被丢掉。窗口大小可以增加,但这会带来两个损失:(1)算法的处理时间会增加,因为它必须为滑动窗口的每个位置进行一次与前向缓存的字符串匹配的工作;(2)<指针>字段必须更长,以允许更长的跳转。
LZSS算法[4]
LZS算法基于LZ77实现,主要由两部分构成,滑窗(Sliding Window)和自适应编码(Adaptive Coding)。压缩处理时,在滑窗中查找与待处理数据相同的块,并用该块在滑窗中的偏移值及块长度替代待处理数据,从而实现压缩编码。如果滑窗中没有与待处理数据块相同的字段,或偏移值及长度数据超过被替代数据块的长度,则不进行替代处理。LZS算法的实现非常简洁,处理比较简单,能够适应各种高速应用。
LZ77通过输出真实字符解决了在窗口中出现没有匹配串的问题,但这个解决方案包含有冗余信息。冗余信息表现在两个方面,一是空指针,二是编码器可能输出额外的字符,这种字符可能包含在下一个匹配串中。LZSS算法以比较有效的方法解决这个问题,它的思想是如果匹配串的长度比指针本身的长度长就输出指针,否则就输出真实字符。由于输出的压缩数据流中包含有指针和字符本身,为了区分它们就需要有额外的标志位,即ID位。
在相同的计算环境下,LZSS算法可获得比LZ77更高的压缩比,而译码同样简单。这也就是为什么这种算法成为开发新算法的基础。许多后来开发的文档压缩程序都使用了LZSS的思想,例如PKZip,ARJ,LHArc和ZOO等等,其差别仅仅是指针的长短、窗口的大小等有所不同。LZSS同样可以和熵编码联合使用,例如ARJ就与霍夫曼编码联用,而PKZip则与Shannon-Fano联用,它的后续版本也采用霍夫曼编码。
LZ78算法[5]
LZ78的编码思想是不断地从字符流中提取新的“缀-符串(String)”(通俗地理解为新“词条”),然后用“代号”也就是码字(Code word)表示这个“词条”。这样一来,对字符流的编码就变成了用码字(Code word)去替换字符流,生成码字流,从而达到压缩数据的目的。与LZ77相比,LZ78的最大优点是在每个编码步骤中减少了缀-符串(String)比较的数目,而压缩率与LZ77类似。
LZW算法[6]
LZW编码是围绕称为词典的转换表来完成的。这张转换表用来存放称为前缀(Prefix)的字符序列,并且为每个表项分配一个码字(Code word),或者叫做序号。这张转换表实际上是把8位ASCII字符集进行扩充,增加的符号用来表示在文本或图像中出现的可变长度ASCII字符串。扩充后的代码可用9位、10位、11位、12位甚至更多的位来表示。Welch的论文中用了12位,12位可以有4096个不同的12位代码,这就是说,转换表有4096个表项,其中256个表项用来存放已定义的字符,剩下3840个表项用来存放前缀(Prefix)。
LZW编码器(软件编码器或硬件编码器)就是通过管理这个词典完成输入与输出之间的转换。LZW编码器的输入是字符流(Charstream),字符流可以是用8位ASCII字符组成的字符串,而输出是用n位(例如12位)表示的码字流(Codestream),码字代表单个字符或多个字符组成的字符串。
LZW算法得到普遍采用,它的速度比使用LZ77算法的速度快,因为它不需要执行那么多的缀-符串比较操作。对LZW算法进一步的改进是增加可变的码字长度,以及在词典中删除老的缀-符串。在GIF图像格式和UNIX的压缩程序中已经采用了加上这些改进措施之后的LZW算法。LZW算法取得了专利,专利权的所有者是美国的一个大型计算机公司—Unisys(优利系统公司),除了商业软件生产公司之外,可以免费使用LZW算法。
重复数据删除[1][7][8]
在备份、归档等实际的存储实践中,人们发现有大量的重复数据块存在,既占用了传输带宽又消耗了相当多的存储资源:有些新文件只是在原有文件上作了部分改动,还有某些文件存在着多份拷贝,如果对所有相同的数据块都只保留一份实例,实际存储的数据量将大大减少--这就是重复数据删除技术的基础。这一做法最早由普林斯顿大学李凯教授(DataDomain的三位创始人之一)提出,称之为全局压缩(Global Compression),并作为容量优化存储推广到商业应用。
重复数据删除(Deduplication)是一种数据缩减技术,可对存储容量进行有效优化。它通过删除数据集中重复的数据,只保留其中一份,从而消除冗余数据,其原理如图4所示。Dedupe技术可以有效提高存储效率和利用率,数据可以缩减到原来的1/20~1/50。这种技术可以很大程度上减少对物理存储空间的需求,减少传输过程中的网络带宽,有效节约设备采购与维护成本。同时它也是一种绿色存储技术,能有效降低能耗。
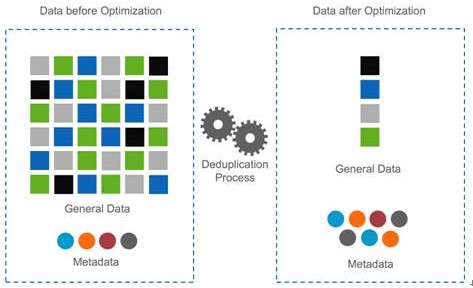
图4 重复数据删除技术原理
Dedupe按照消重的粒度可以分为文件级和数据块级。文件级的dedupe技术也称为单一实例存储(SIS, Single Instance Store),数据块级的重复数据删除,其消重粒度更小,可以达到4-24KB之间。显而易见,数据块级可以提供更高的数据消重率,因此目前主流的 dedupe产品都是数据块级的。Dedupe将文件分割成定长或变长的数据块,采用MD5/SHA1等Hash算法为数据块计算指纹(FP, Fingerprint)。可以同时使用两种及以上hash算法计算数据指纹,以获得非常小的数据碰撞发生概率。具有相同指纹的数据块即可认为是相同的数据块,存储系统中仅需要保留一份。这样,一个物理文件在存储系统就对应一个逻辑表示,由一组FP组成的元数据。当进行读取文件时,先读取逻辑文件,然后根据FP序列,从存储系统中取出相应数据块,还原物理文件副本。
Dedupe技术可以帮助众多应用降低数据存储量,节省网络带宽,提高存储效率,减小备份窗口,有效节省成本。Dedupe技术目前最成功的应用领域是数据备份、容灾和归档系统,然而事实上dedupe技术可以用于很多场合,包括在线数据、近线数据、离线数据存储系统,可以在文件系统、卷管理器、NAS、SAN中实施。Dedupe也可以用数据传输与同步,作为一种数据压缩技术可用于数据打包。为什么dedupe技术最成功的应用是数据备份领域,而其他领域应用很少呢?这主要由两方面的原因决定的,一是数据备份应用对数据进行多次备份后,存在大量重复数据,非常适合这种技术。二是dedupe技术的缺陷,主要是数据安全、性能。Dedupe使用hash指纹来识别相同数据,存在产生数据碰撞并导致数据不一致性的可能性。Dedupe需要进行数据块切分、数据块指纹计算和数据块检索,消耗可观的系统资源,对存储系统性能产生影响。
Dedupe的衡量维度主要有两个,即重复数据删除率(Deduplication ratios)和性能。Dedupe性能取决于具体实现技术,而重复数据删除率则由数据自身的特征和应用模式所决定,目前各存储厂商公布的重复数据删除率从20:1到500:1不等。对何种数据进行消重,时间数据还是空间数据,全局数据还是局部数据?何时进行消重,在线还是离线?在何处进行消重,源端还是目标端?如何进行消重?实际应用Dedupe技术时应该考虑各种因素,因为这些因素会直接影响其性能和效果。另外值得一得的是,hash碰撞问题现在还没有根本的解决方法,因此对于关键业务数据应该慎重考虑应用dedupe技术。
存储系统的重复数据删除过程一般是这样的:首先将数据文件分割成一组数据块,为每个数据块计算指纹,然后以指纹为关键字进行Hash查找,匹配则表示该数据块为重复数据块,仅存储数据块索引号,否则则表示该数据块是一个新的唯一块,对数据块进行存储并创建相关元信息。这样,一个物理文件在存储系统就对应一个逻辑表示,由一组FP组成的元数据。当进行读取文件时,先读取逻辑文件,然后根据FP序列,从存储系统中取出相应数据块,还原物理文件副本。从如上过程中可以看出,Dedupe的关键技术主要包括文件数据块切分、数据块指纹计算和数据块检索。
重复数据删除技术的关键在于数据块"指纹"的生成和鉴别。数据块"指纹"是鉴别数据块是否重复的依据,如果不同数据块的"指纹"相同,就会造成内容丢失,产生不可恢复的严重后果。在目前的实际应用中,一般都选择MD5或SHA-1等标准杂凑(hash)算法生成的数据块的摘要(digest)作为"指纹",以区分不同数据块间存在的差异,从而保证不同数据块之间不会发生冲突。但是,MD5,SHA-1等算法的计算过程非常复杂,纯软件计算很难满足存储应用的性能需求,"指纹"的计算往往成为重复数据删除应用的性能瓶颈。
数据压缩与重复数据删除对比分析
数据压缩和重复数据删除技术都着眼于减少数据量,其差别在于数据压缩技术的前提是信息的数据表达存在冗余,以信息论研究作为基础;而重复数据删除的实现依赖数据块的重复出现,是一种实践性技术。然而,通过上面的分析我们发现,这两种技术在本质上却是相同的,即通过检索冗余数据并采用更短的指针来表示来实现缩减数据容量。它们的区别关键在于,消除冗余范围不同,发现冗余方法不同,冗余粒度不同,另外在具体实现方法有诸多不同。
(1)消除冗余范围
数据压缩通常作用于数据流,消除冗余范围受到滑动窗口或缓存窗口的限制。由于考虑性能因素,这个窗口通常是比较小的,只能对局部数据产生作用,对单个文件效果明显。重复数据删除技术先对所有数据进行分块,然后以数据块为单位在全局范围内进行冗余消除,因此对包含众多文件的全局存储系统,如文件系统,效果更加显著。如果把数据压缩应用于全局,或者把重复数据删除应用于单个文件,则数据缩减效果要大大折扣。
(2)发现冗余方法
数据压缩主要通过串匹配来检索相同数据块,主要采用字符串匹配算法及其变种,这是精确匹配。重复数据删除技术通过数据块的数据指纹来发现相同数据块,数据指纹采用hash函数计算获得,这是模糊匹配。精确匹配实现较为复杂,但精度高,对细粒度消除冗余更为有效;模糊匹配相对简单许多,对大粒度的数据块更加适合,精度方面不够。
(3)冗余粒度
数据压缩的冗余粒度会很小,可以到几个字节这样的小数据块,而且是自适应的,不需要事先指定一个粒度范围。重复数据删除则不同,数据块粒度比较大,通常从512到8K字节不等。数据分块也不是自适应的,对于定长数据块需要事先指定长度,变长数据分块则需要指定上下限范围。更小的数据块粒度会获得更大的数据消冗效果,但计算消耗也更大。
(4)性能瓶颈
数据压缩的关键性能瓶颈在于数据串匹配,滑动窗口或缓存窗口越大,这个计算量就会随之大量增加。重复数据删除的性能瓶颈在于数据分块与数据指纹计算,MD5/SHA-1等hash函数的计算复杂性都非常高,非常占用CPU资源。另外,数据指纹需要保存和检索,通常需要大量内存来构建hash表,如果内存有限则会对性能产生严重影响。
(5)数据安全
这里的数据压缩都是无损压缩,不会发生数据丢失现象,数据是安全的。重复数据删除的一个问题是,利用hash产生的数据块指纹可能会产生的碰撞,即两个不同的数据块生成了相同的数据指纹。这样,就会造成一个数据块丢失的情况发生,导致数据发生破坏。因此,重复数据删除技术存在数据安全隐患。
(6)应用角度
数据压缩直接对流式数据进行处理,不需要事先对全局信息进行分析统计,可以很好地利用流水线或管道方式与其他应用结合使用,或以带内方式透明地作用于存储系统或网络系统。重复数据删除则需要对数据进行分块处理,需要对指纹进行存储和检索,需要对原先物理文件进行逻辑表示。如果现有系统要应用这种技术,则需要对应用进行修改,难以做到透明实现。目前重复数据删除并不是一个通常功能,而更多地以产品形态出现,如存储系统、文件系统或应用系统。因此,数据压缩是一种标准功能,而重复数据删除现在还没有达到这种标准,应用角度来看,数据压缩更为简单。
珠联璧合
数据压缩与重复数据删除两种技术具有不同层面的针对性,并能够结合起来使用,从而实现更高的数据缩减比例。值得一提的是,如果同时应用数据压缩和重复数据删除技术,为了降低对系统的处理需求和提高数据压缩比率,通常需要先应用数据删除技术,然后再使用数据压缩技术进一步降低"结构图"和基本数据块的体积。如果顺序颠倒会出现什么样的结果呢?压缩会对数据进行重新编码,从而破坏了数据原生的冗余结构,因此再应用重复数据删除效果则会大打折扣,而且消耗时间也更多。而先执行重复数据删除则不同,它首先消除了冗余数据块,然后应用数据压缩对唯一副本数据块进行再次压缩。这样,两种技术的数据缩减作用得到叠加,而且数据压缩的消耗时间大大降低。因此,先去重后压缩,可以获得更高的数据压缩率和性能。这里我们以gzip和作者自己实现的开源小软件deduputil[8]来验证这个应用经验。
原始数据:linux-2.6.37内核源码,du -h的容量为1107724KB,约1081.8MB。
对linux-2.6.37目录执行time gzip -c -r linux-2.6.37 > linux-2.6.37.gz,压缩得到linux-2.6.37.gz,容量约为264MB,消耗时间152.776s;
对linux-2.6.37目录执行time dedup -c -b 4096 linux-2.6.37.ded linux-2.6.37,去重得到linux-2.6.37.ded,容量约为622MB,消耗时间28.890s;
对linux-2.6.37.gz执行time dedup -c -b 4096 linux-2.6.37.gz.ded linux-2.6.37.gz,去重得到linux-2.6.37.gz.ded,容量约为241MB,消耗时间7.216;
对linux-2.6.37.ded执行time gzip -c linux-2.6.37.ded > linux-2.6.37.ded.gz,压缩得到linux-2.6.36.ded.gz,容量约为176MB,消耗时间38.682;
经过实验可得,dedup + gzip得到的linux-2.6.37.ded.gz容量为176MB,消耗时间为67.572秒;gzip + dedup得到的linux-2.6.37.gz.ded容量为241MB,消耗时间为159.992秒。实验数据进一步验证了上述的分析,先数据去重再数据压缩,能够获得更高的数据压缩率和性能。
参考阅读
1 数据缩减技术 http://tech.watchstor.com/management-116492.htm
2 数据压缩原理 http://jpkc.zust.edu.cn/2007/dmt/course/MMT03_05_1.htm
3 LZ77算法 http://jpkc.zust.edu.cn/2007/dmt/course/MMT03_05_2.htm
4 LZSS算法 http://jpkc.zust.edu.cn/2007/dmt/course/MMT03_05_3.htm
5 LZ78算法 http://jpkc.zust.edu.cn/2007/dmt/course/MMT03_05_4.htm
6 LZW算法 http://jpkc.zust.edu.cn/2007/dmt/course/MMT03_05_5.htm
7 重复数据删除技术研究 http://blog.csdn.net/liuben/archive/2010/08/21/5829083.aspx
8 高效存储技术研究 http://blog.csdn.net/liuben/archive/2010/12/08/6064045.aspx
8 Deduputil http://sourceforge.net/projects/deduputil/
分享到:






相关推荐
深入理解数据压缩与重复数据删除.docx
3.3.1 修改数据库语法 3.3.2 使用SQL语句修改数据库 3.4 管理数据库 3.4.1 扩充与压缩数据库 3.4.2 导入与导出数据 3.4.3 数据库的备份与恢复 3.4.4 使用sp_helpdb查看数据库信息 3.5 小结第4章 数据表的相关操作 ...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
他博学多才,对关系理论有深入的理解,有9年解决复杂sQL问题的实战经验。Anthony通晓新的和功能强大的sQL功能,比如,添加到最新sQL标准中的窗口函数语法等。 --------------------------------------------------...
他博学多才,对关系理论有深入的理解,有9年解决复杂sQL问题的实战经验。Anthony通晓新的和功能强大的sQL功能,比如,添加到最新sQL标准中的窗口函数语法等。 --------------------------------------------------...
属性 29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 ...
属性 29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 ...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
属性 29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 ...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
属性 29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 ...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
29212.7.1 为数据输入而改变字段的次序 29212.7.2 从Tab键次序中删除字段 29312.8 现实世界—窗体设计技巧 293第13章 设计自定义多表窗体 29613.1 扩展你的窗体设计技能 29613.2 了解Access工具箱 29613.2.1 控件...
书中还深入讲述了其他ASP.NET图书遗漏的高级主题,如自定义控件的创建、图像处理、加密等。此外,《ASP.NET 4高级程序设计(第4版)》专门提供了两章的内容来教你如何用Ajax 技术制作快速响应的页面,以及如何使用微软...
书中还深入讲述了其他ASP.NET图书遗漏的高级主题,如自定义控件的创建、图像处理、加密等。此外,《ASP.NET 4高级程序设计(第4版)》专门提供了两章的内容来教你如何用Ajax 技术制作快速响应的页面,以及如何使用微软...